Platform Overview
Fuzzing Terminology
Install the Fuzzbuzz CLI
Find your first C/C++ bug
Find your first Python bug
Find your first Rust bug
Find your first Go bug
Protocol Fuzzing
Seeding your fuzzer
Integrating with libFuzzer
Heartbleed in 5 Minutes
GitHub Integration
GitLab Integration
CLI Integration
fuzzbuzz.yaml reference
Fuzzer Reference
Bug Types
Self-Hosted Fuzzbuzz
Overview
Getting Started
Guides
Tutorials
Integrations
Reference
Platform Overview
Workflow
The Fuzzbuzz workflow is very similar to other CI/CD testing workflows.
However, unlike other testing workflows, fuzz testing requires multiple jobs to run simultaneously, which results in a few extra steps. Here's a high level overview of what that looks like.

In short:
- Push code to your Fuzzbuzz-integrated Git repository or CI/CD.
- Code is built and instrumented by Fuzzbuzz as soon as a change is detected
- Instrumented application is distributed across the available VMs and fuzz testing begins.
- Bugs & fuzzing stats are aggregated and processed.
- Data is categorized, deduplicated and saved to the Fuzzbuzz DB.
- Notifications are sent if any bugs are detected.
- Developer is alerted with bug details, and a reproducible test case.
Feature breakdown
GitHub Integration
Fuzzbuzz integrates with GitHub for source code and git access. Any changes that are made to your repository on GitHub are synced with Fuzzbuzz.
Once connected, GitHub will notify Fuzzbuzz of any updates (ie, new commits or Pull Requests), which will trigger a new job to start on your latest changes.
Continuous Jobs
Continuous jobs are run on your main or master branch. This allows the fuzzer to make meaningful progress in understanding your application's input structure.
Depending on the complexity of the code you're fuzzing, it may take a couple hours or days for the fuzzer to find bugs, which is why we encourage running at least 1 continuous job.
There are only 2 ways a continuous job is stopped:
- a user manually stops it
- Fuzzbuzz has determined that the job is unlikely to find any more bugs, and will stop the job until a new commit is merged
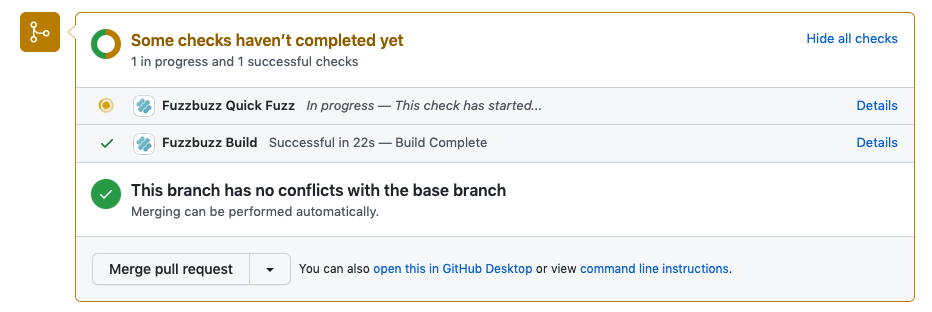
Pull Request Jobs
Pull Request Jobs run for a preconfigured amount of time (default 15 minutes) on every Pull Request as a way to check code for regressions and catch low hanging bugs.
A GitHub Check will also appear on the PR being tested. Any detected bugs will block merging until they are fixed.
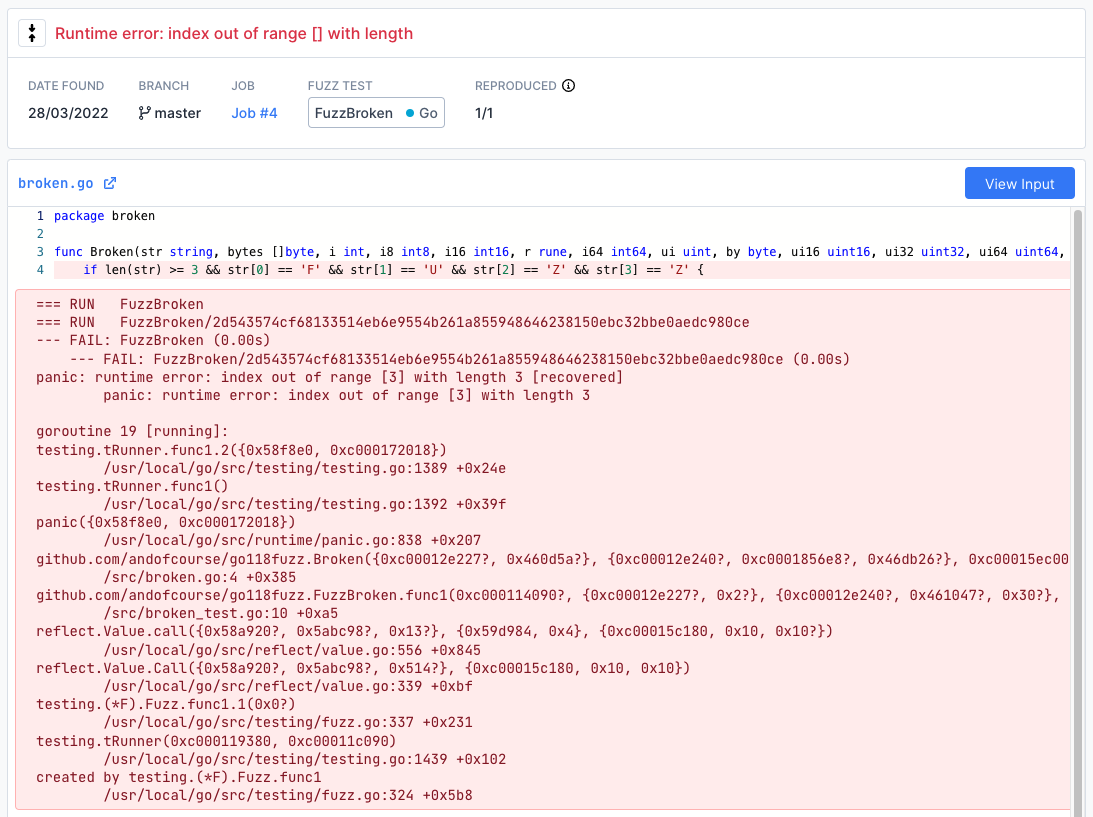
Bug Viewer
All bugs that have been detected will show up here.
Fuzzbuzz stores a variety of data in order to make it trivial to reproduce and fix bugs. When bugs are found, you are presented with:
- the stacktrace
- the file and line it occurred on
- a reproducible test case
- the number of times Fuzzbuzz was able to reproduce it
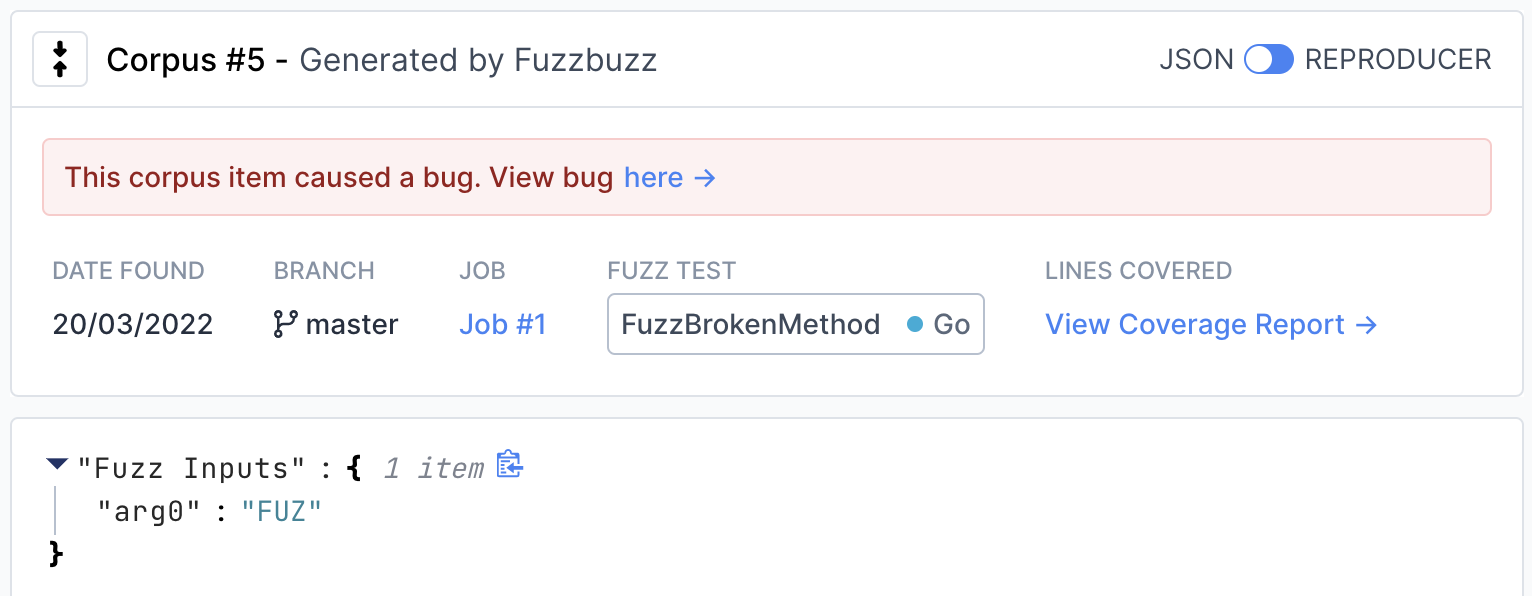
Corpus Viewer
As your fuzz test generates corpus inputs, they will be viewable in Hex or JSON format. You can also download corpus inputs as reproducible tests that you can run in your local developer environment.
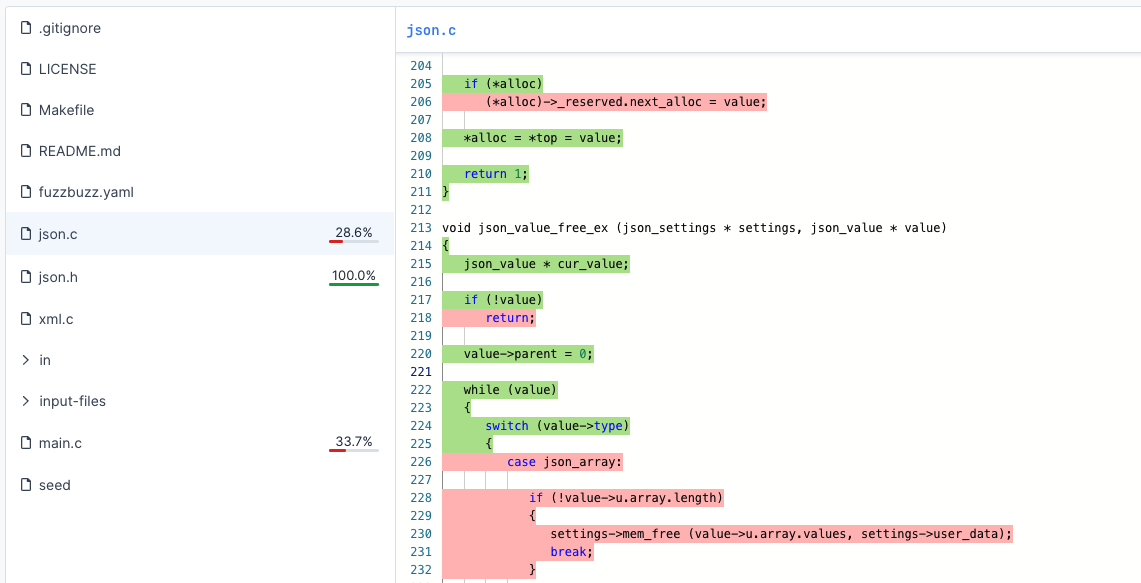
Code Coverage Viewer
When fuzzing, it can be difficult to know how effective your test is, where it's getting stuck or if it's doing anything at all.
Fuzzbuzz has a built-in coverage explorer that overlays coverage generated by your corpus directly on top of your source code, so you can dig into your fuzz test's progress.